

State management considerations in high-traffic taxi booking apps
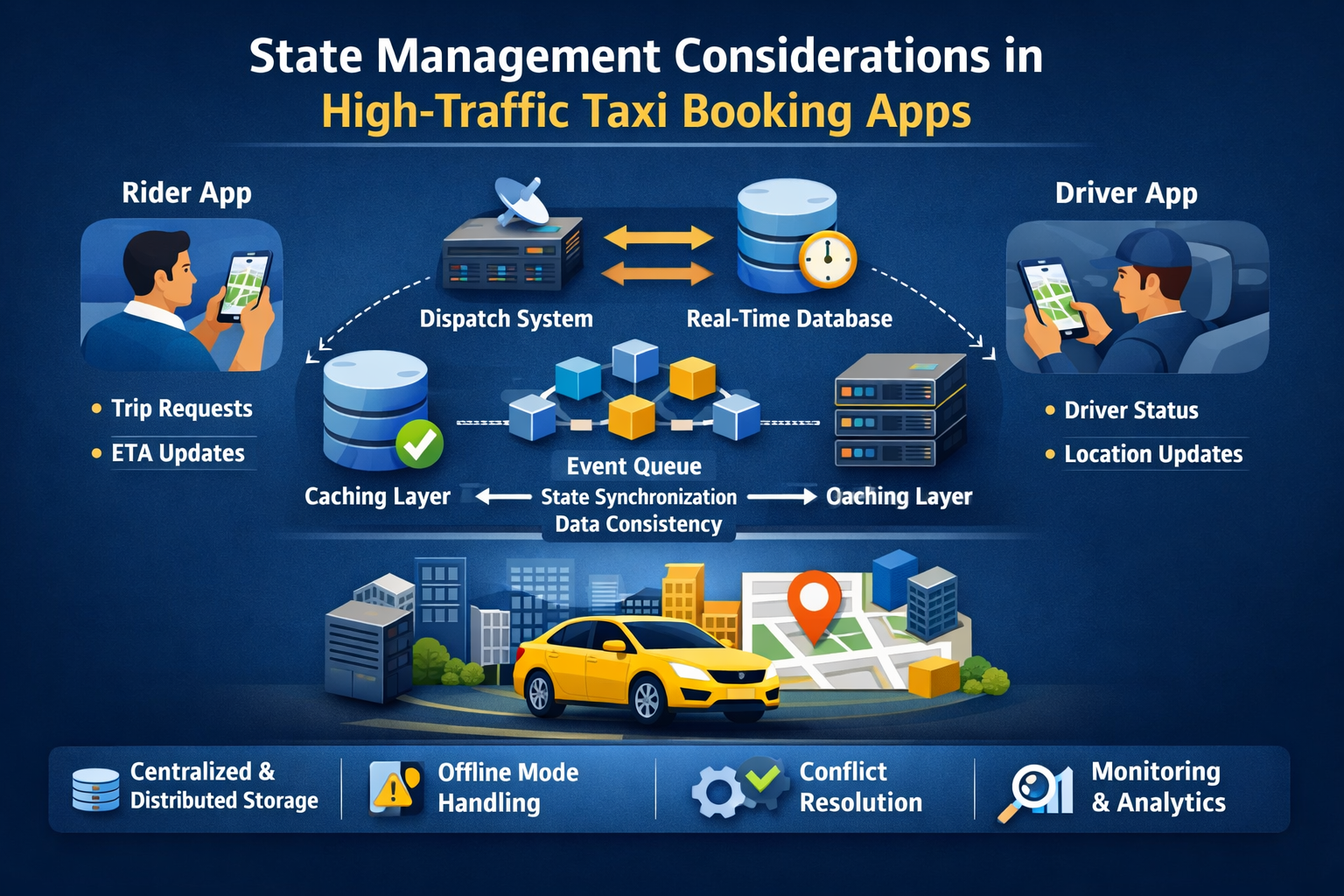
Modern ride-hailing platforms operate in highly dynamic environments where thousands of concurrent users interact with drivers, pricing engines, and location services in real time. Efficient state management ensures consistent trip data, reliable driver availability updates, and seamless passenger experiences even during demand spikes. As mobility ecosystems expand across cities and regions, engineering teams must design robust synchronization mechanisms and scalable infrastructure patterns that support continuous booking operations without latency, duplication, or transactional inconsistencies across distributed components.
Understanding state management in real time ride systems architecture
State management in ride-hailing platforms refers to the controlled handling of application data across sessions, services, and devices. Every booking request, driver location update, fare calculation, and payment confirmation represents a state transition that must remain consistent across multiple systems.
In high-traffic mobility platforms, state transitions occur across several layers:
-
Rider application state
-
Driver application state
-
Dispatch system state
-
Payment processing state
-
Trip lifecycle state
When these layers fall out of synchronization, the result may include duplicate bookings, incorrect driver assignments, or inconsistent fare calculations.
A taxi booking app development company designing scalable systems must treat state as a distributed systems challenge rather than a simple application variable. Stateless APIs combined with durable storage layers and message-driven coordination often form the foundation of reliable booking workflows.
The architecture must also support real-time updates without compromising transactional integrity, especially when thousands of rides are requested simultaneously during peak hours.
Challenges of synchronizing driver and rider app states reliably
The most complex aspect of mobility platform engineering is maintaining synchronization between independent mobile clients and backend services. Drivers and riders operate on separate devices, networks, and application sessions, making eventual consistency a core design concern.
Common synchronization challenges include:
-
Network latency causing delayed ride confirmations
-
Location update collisions during peak demand
-
Driver availability mismatches
-
Duplicate booking attempts
-
Partial transaction failures
For example, when a rider confirms a booking while a driver simultaneously changes availability status, the dispatch system must resolve the conflict deterministically.
State synchronization becomes even more difficult when systems scale across multiple regions. Backend services must ensure that trip state changes propagate instantly across dispatch engines, analytics pipelines, and billing systems.
Engineering teams at a taxi booking app development company often rely on message queues, distributed caches, and transactional databases to maintain consistency without introducing performance bottlenecks.
Careful orchestration of state transitions prevents race conditions that could otherwise degrade user trust in the platform.
Centralized versus distributed state storage strategies comparison
Choosing between centralized and distributed state storage significantly affects scalability and reliability.
Centralized state storage offers:
-
Simplified consistency management
-
Easier debugging and auditing
-
Strong transactional guarantees
However, centralized storage can become a bottleneck during peak booking periods.
Distributed state storage, on the other hand, enables:
-
Horizontal scalability
-
Fault tolerance
-
Reduced latency across geographic regions
Yet distributed systems introduce complexity in conflict resolution and replication strategies.
Many mobility platforms adopt hybrid approaches. For example, trip lifecycle data may be stored in transactional databases, while driver location data is maintained in distributed in-memory stores.
This separation ensures that critical financial transactions remain strongly consistent, while rapidly changing telemetry data remains highly available.
Architectural decisions also influence the cost to build taxi app infrastructure, since distributed storage systems typically require additional monitoring, replication, and failover mechanisms.
Selecting the correct storage model depends on expected ride volume, geographic coverage, and real-time performance requirements.
Role of caching layers in high demand ride matching flows optimization
Caching plays a vital role in reducing latency in ride-matching operations. Dispatch systems frequently access driver proximity data, pricing multipliers, and routing calculations, which can overwhelm databases if not cached effectively.
Strategic caching improves performance in the following areas:
-
Driver availability lookup
-
Surge pricing calculations
-
Route estimation services
-
Trip history retrieval
-
Session management
In-memory data stores help maintain temporary state snapshots that update continuously without requiring database writes for every location change.
However, cache invalidation becomes a critical concern. Incorrect cache expiration policies may result in outdated driver locations or inaccurate fare estimates.
To mitigate these risks, systems typically implement:
-
Time-based expiration policies
-
Event-triggered invalidation
-
Write-through caching models
-
Region-aware caching strategies
A taxi booking app development company must carefully balance cache freshness with performance gains, especially in metropolitan environments where driver movement updates occur every few seconds.
Caching strategies directly influence ride allocation accuracy and overall system responsiveness.
Event driven architecture for scalable booking workflows design
Event-driven architecture enables scalable coordination between services responsible for booking, dispatch, billing, and notifications. Instead of relying on synchronous communication, services publish state changes as events that downstream systems consume asynchronously.
Typical events in ride-hailing platforms include:
-
Ride requested
-
Driver assigned
-
Driver arrived
-
Trip started
-
Trip completed
-
Payment processed
This architecture provides several advantages:
-
Loose coupling between services
-
Improved system resilience
-
Scalable state propagation
-
Better failure isolation
Message brokers and event logs ensure that state transitions are recorded reliably and replayed if necessary.
For example, if the billing service temporarily fails, the completed trip event remains available for later processing without losing transaction data.
Event sourcing patterns can also reconstruct trip state history for analytics and auditing purposes.
These patterns are especially useful in platforms built using modular microservices or a white label taxi app architecture where multiple clients rely on shared backend infrastructure.
Handling offline mode and data reconciliation processes securely
Drivers frequently operate in areas with unstable network connectivity. Offline functionality must preserve booking integrity while allowing drivers to continue operating temporarily.
Offline state management typically involves:
-
Local storage of trip updates
-
Deferred synchronization
-
Conflict detection logic
-
Timestamp-based reconciliation
When connectivity resumes, the application reconciles local changes with the server state.
Common reconciliation strategies include:
-
Last-write-wins policies
-
Server-authoritative conflict resolution
-
Operational transformation techniques
-
Version-controlled state updates
Security is equally important. Locally stored trip data must be encrypted to prevent unauthorized access.
Offline resilience ensures that temporary connectivity disruptions do not interrupt ride completion workflows or payment recording.
A taxi booking app development company designing driver applications must ensure that offline state transitions never compromise billing accuracy or trip history consistency.
Robust reconciliation pipelines protect both riders and drivers from data loss during network failures.
Monitoring state consistency across microservices layers continuously
Observability tools help engineering teams detect state inconsistencies before they affect users. Monitoring distributed state requires visibility across APIs, databases, queues, and mobile clients.
Key monitoring practices include:
-
Distributed tracing across booking workflows
-
Real-time anomaly detection
-
State transition logging
-
Consistency validation checks
-
Replication lag monitoring
Metrics pipelines track how long state changes take to propagate between services. If driver assignment events lag behind booking confirmations, dispatch reliability may suffer.
Modern monitoring stacks often combine logging systems, metrics dashboards, and trace visualizations to diagnose state propagation issues.
Testing environments also play a crucial role. Simulating high-demand ride scenarios helps identify bottlenecks in synchronization pipelines.
Continuous monitoring ensures that distributed state systems remain predictable even during traffic surges, large events, or regional outages.
Reliable observability reduces debugging time and improves platform stability.
Future directions in resilient mobility platform state design patterns
Mobility platforms continue evolving toward more resilient state management models. Advances in distributed computing and real-time streaming technologies are shaping the next generation of ride-hailing infrastructure.
Emerging trends include:
-
Conflict-free replicated data types for synchronization
-
Edge computing for driver proximity calculations
-
Streaming databases for trip lifecycle tracking
-
Deterministic state machines for booking workflows
-
AI-assisted anomaly detection in dispatch systems
Serverless orchestration and globally distributed databases are also reducing operational complexity while improving availability.
Engineering teams increasingly design systems that tolerate partial failures without interrupting ride booking operations.
State management is becoming less about storage and more about coordination across autonomous services.
As urban mobility ecosystems integrate public transit, logistics, and autonomous vehicles, state models must support multi-modal trip coordination and real-time demand balancing across transportation networks.
Conclusion
State management remains a foundational engineering concern in large-scale mobility platforms handling real-time booking activity. Synchronizing rider interactions, driver availability, trip lifecycle events, and payment systems requires disciplined architectural planning and continuous monitoring. Distributed storage models, event-driven workflows, caching strategies, and reconciliation mechanisms together ensure that booking systems remain consistent and reliable under heavy demand. As transportation platforms grow in complexity and scale, resilient state coordination will continue to determine system stability, user trust, and operational efficiency across mobility ecosystems.